Groot: Generating Robust Watermark for Diffusion-Model-Based Audio Synthesis
Author
Weizhi Liu1, Yue Li1, Dongdong Lin2, Hui Tian1, Haizhou Li3.
1Huaqiao University and Xiamen Key Laboratory of Data Security and Blockchain Technology, Xiamen, China.
2Shenzhen University, Shenzhen, China.
3The Chinese University of Hong Kong, Shenzhen, China.
Abstract
Amid the burgeoning development of generative models like diffusion models, the task of differentiating synthesized audio from its natural counterpart grows more daunting. Deepfake detection offers a viable solution to combat this challenge. Yet, this defensive measure unintentionally fuels the continued refinement of generative models. Watermarking emerges as a proactive and sustainable tactic, preemptively regulating the creation and dissemination of synthesized content. Thus, this paper, as a pioneer, proposes the generative robust audio watermarking method (Groot), presenting a paradigm for proactively supervising the synthesized audio and its source diffusion models. In this paradigm, the processes of watermark generation and audio synthesis occur simultaneously, facilitated by parameter-fixed diffusion models equipped with a dedicated encoder. The watermark embedded within the audio can subsequently be retrieved by a lightweight decoder. The experimental results highlight Groot’s outstanding performance, particularly in terms of robustness, surpassing that of the leading state-of-the-art methods. Beyond its impressive resilience against individual post-processing attacks, Groot exhibits exceptional robustness when facing compound attacks, maintaining an average watermark extraction accuracy of around 95%.
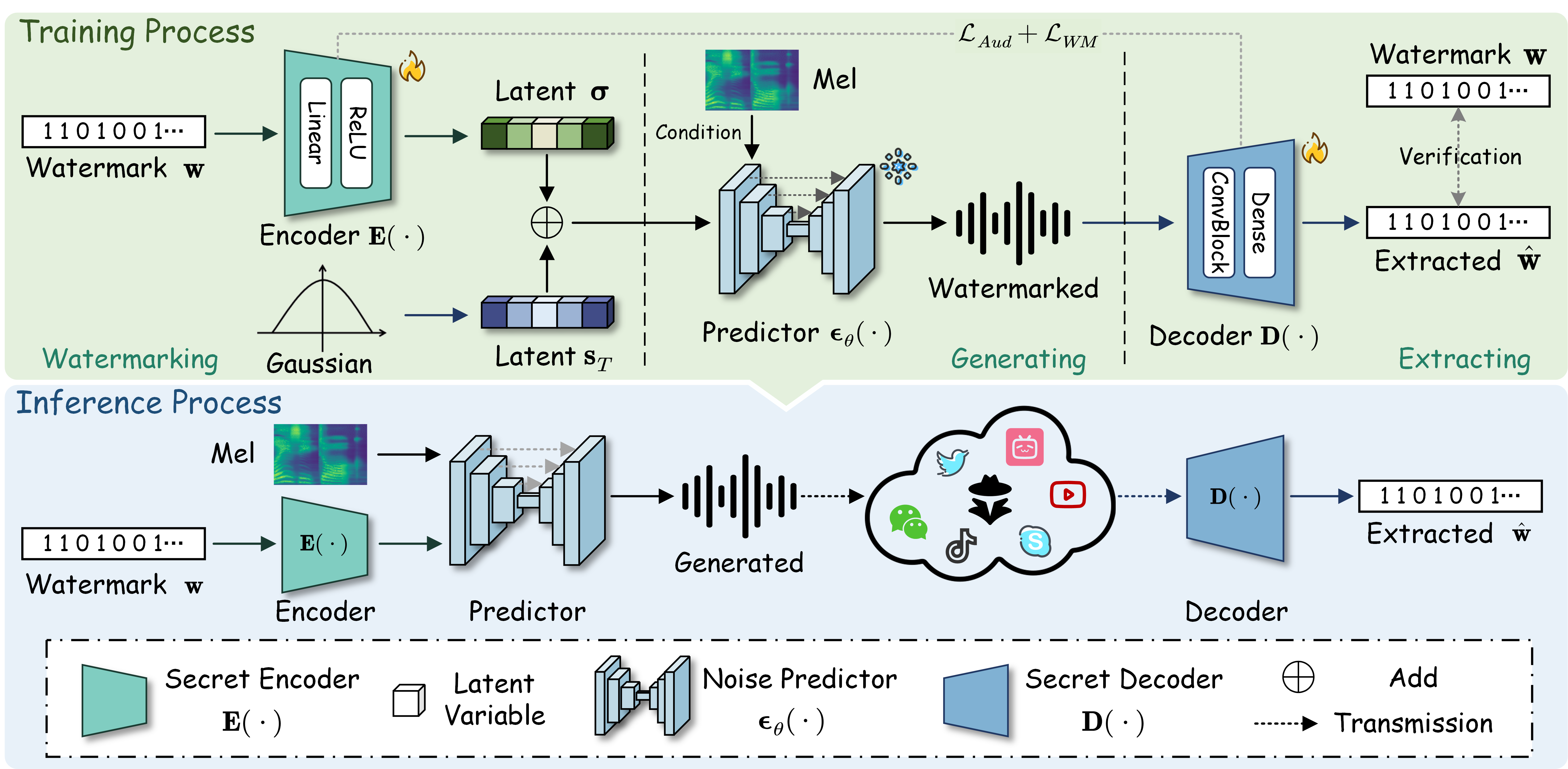
Pipeline of Groot
Audio Demo
Single-Speaker English Dataset (LJSpeech)
| DiffWave[1] | Demo1 | Demo2 | Demo3 | Demo4 | Demo5 |
|---|---|---|---|---|---|
| Generated | |||||
| Watermarked | |||||
| Mel | 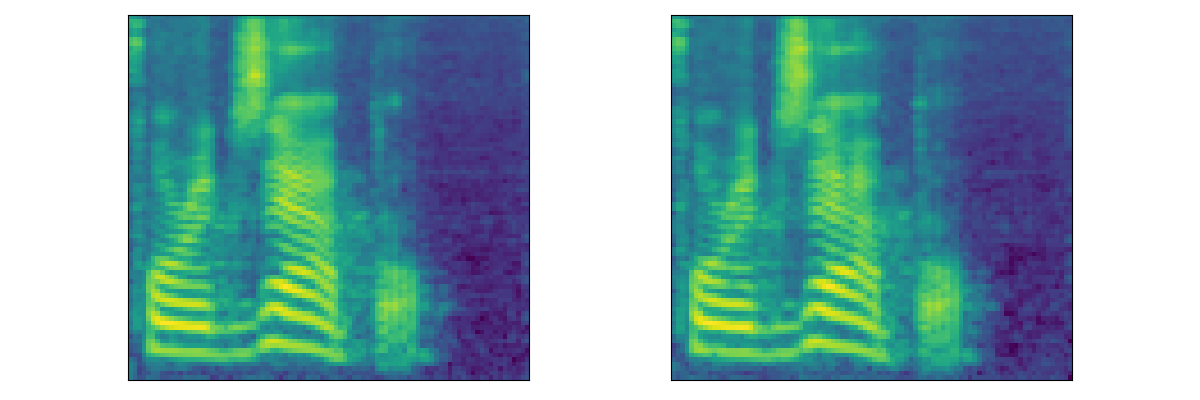 |
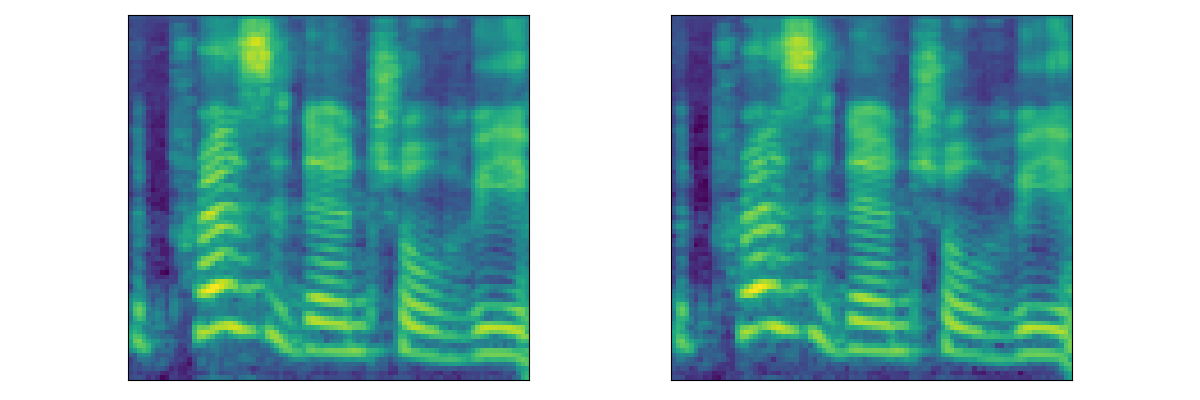 |
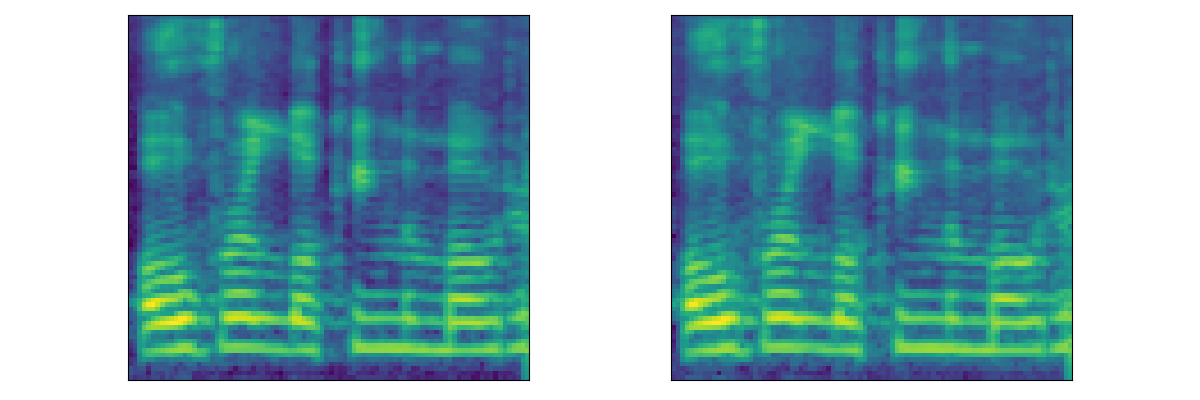 |
 |
 |
| WaveGrad[2] | Demo1 | Demo2 | Demo3 | Demo4 | Demo5 |
|---|---|---|---|---|---|
| Generated | |||||
| Watermarked | |||||
| Mel |  |
 |
 |
 |
 |
| PriorGrad[3] | Demo1 | Demo2 | Demo3 | Demo4 | Demo5 |
|---|---|---|---|---|---|
| Generated | |||||
| Watermarked | |||||
| Mel |  |
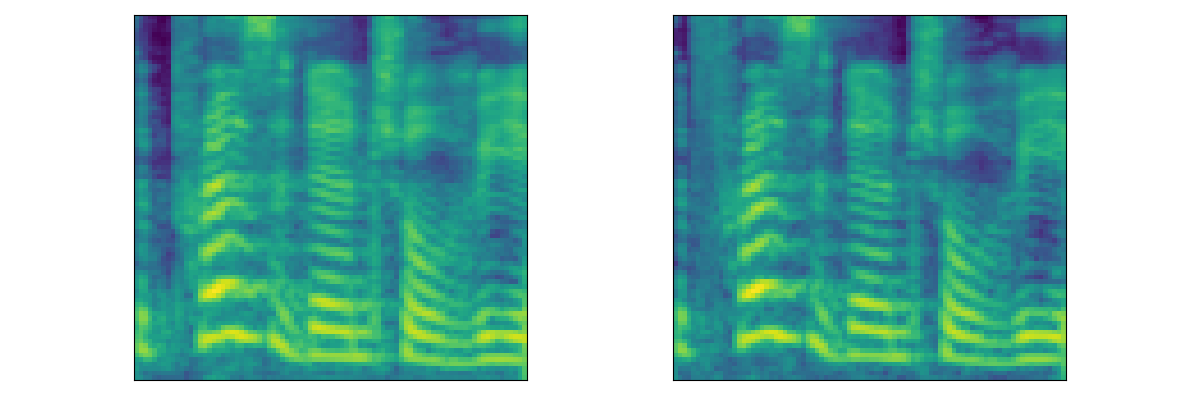 |
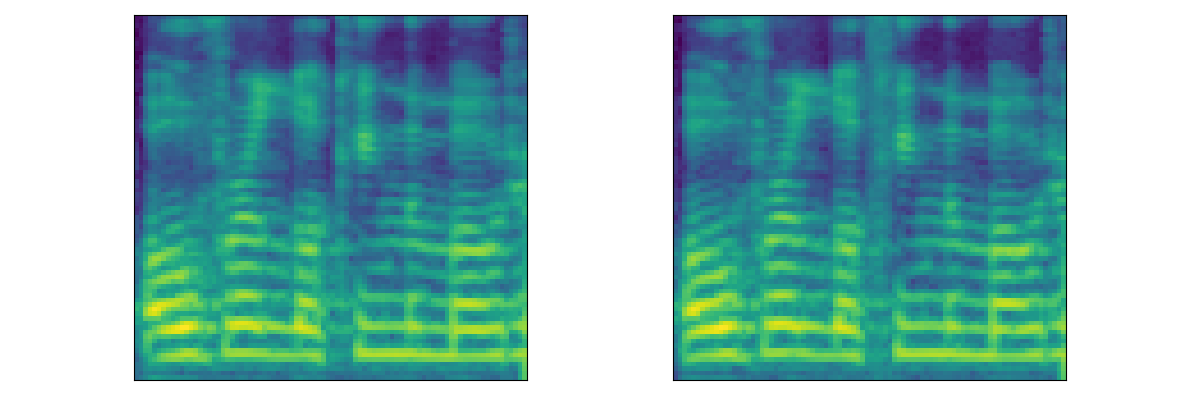 |
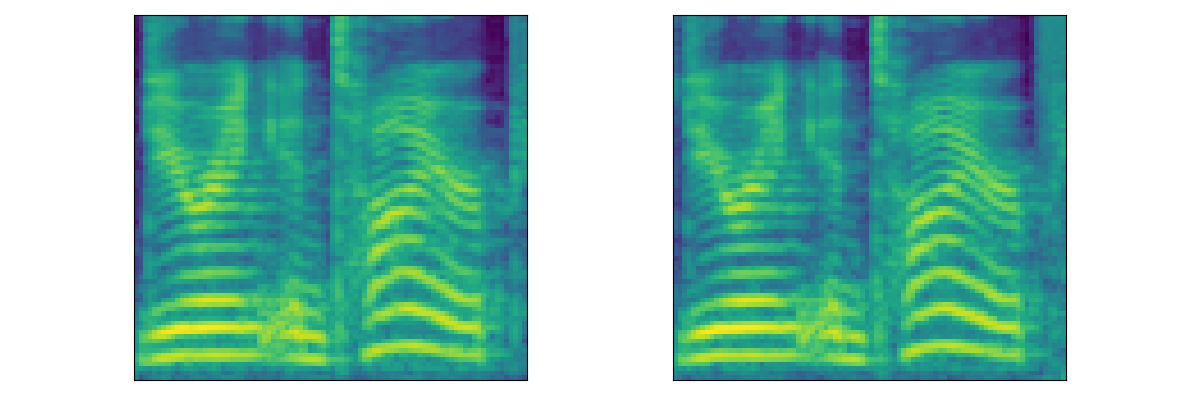 |
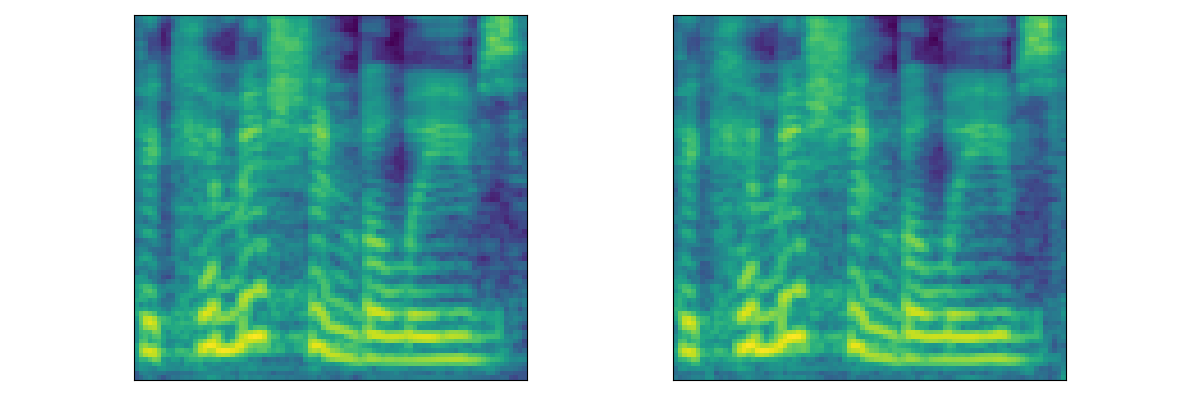 |
Multi-Speaker English Dataset (LibriTTS)
| DiffWave | Speaker1 | Speaker2 | Speaker3 | Speaker4 | Speaker5 |
|---|---|---|---|---|---|
| Generated | |||||
| Watermarked | |||||
| Mel | 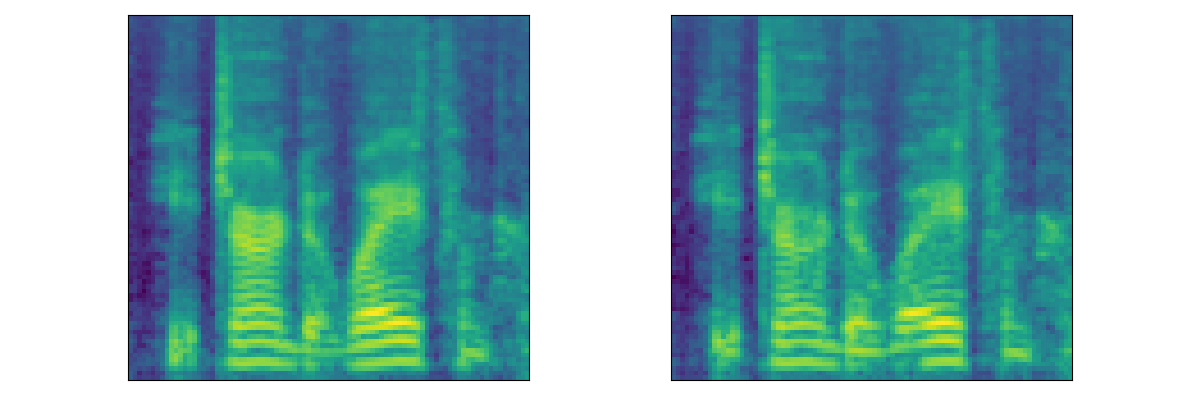 |
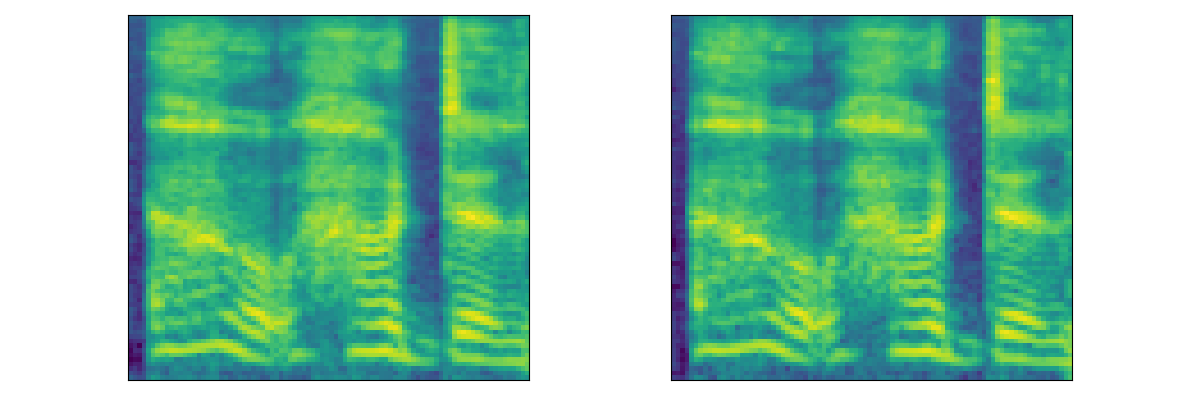 |
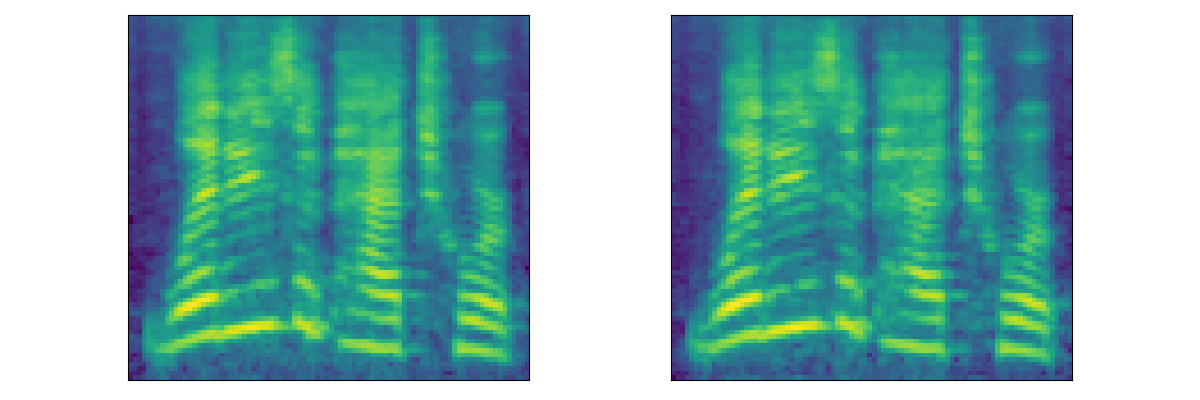 |
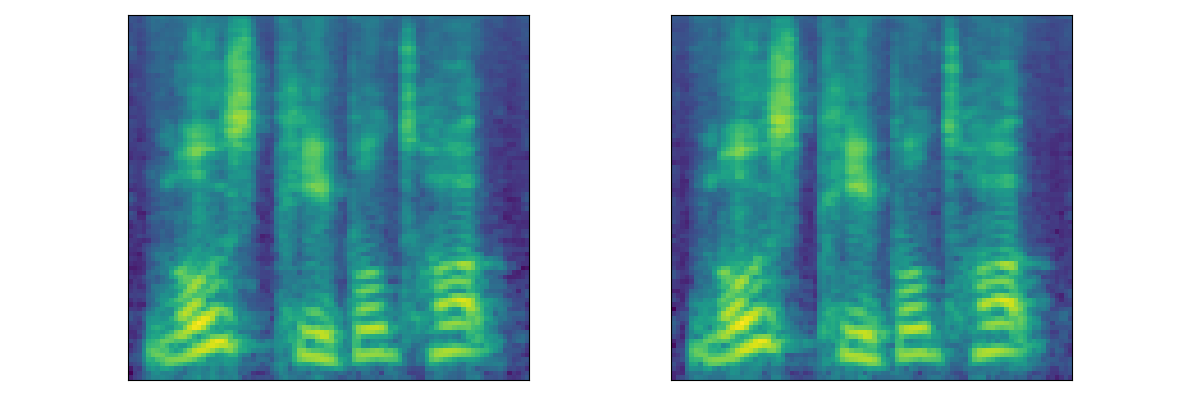 |
 |
Multi-Speaker English Dataset (LibriSpeech)
| DiffWave | Speaker1 | Speaker2 | Speaker3 | Speaker4 | Speaker5 |
|---|---|---|---|---|---|
| Generated | |||||
| Watermarked | |||||
| Mel |  |
 |
 |
 |
 |
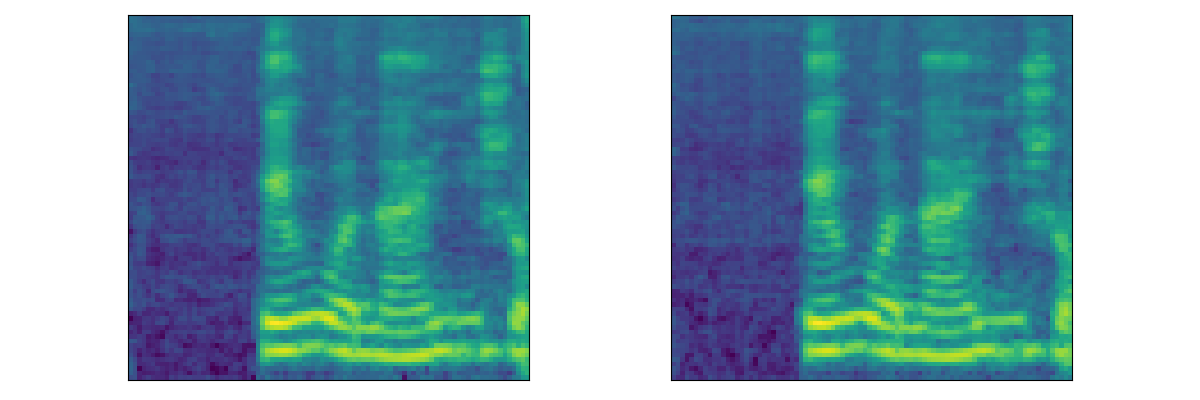
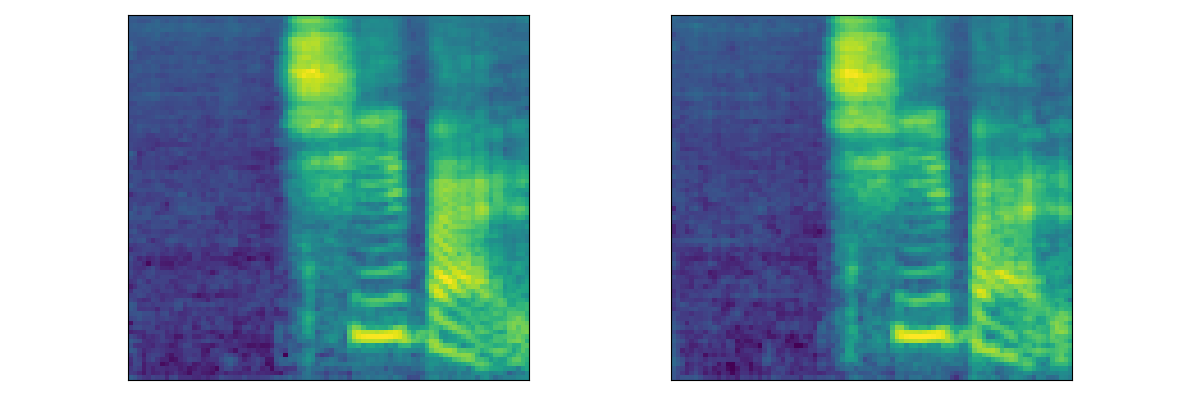
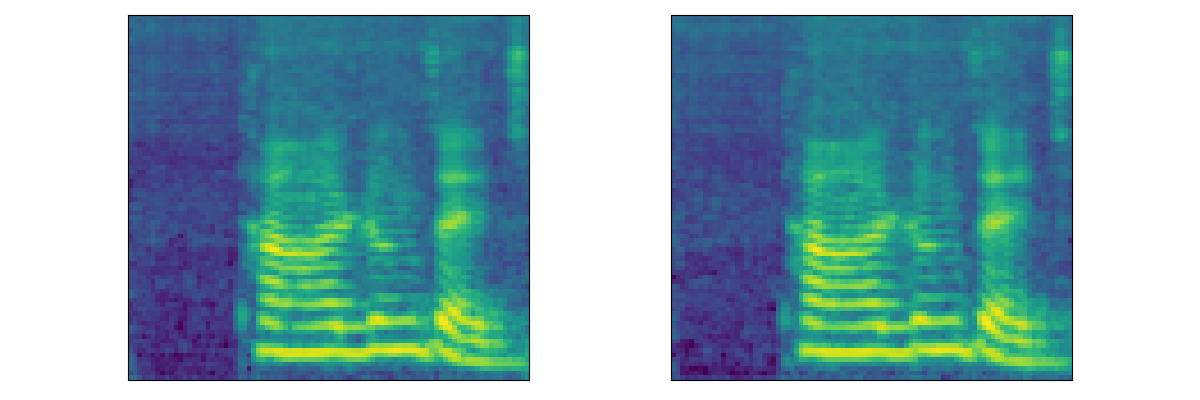
Multi-Speaker Chinese Dataset (Aishell3)
| DiffWave | Speaker1 | Speaker2 | Speaker3 | Speaker4 | Speaker5 |
|---|---|---|---|---|---|
| Generated | |||||
| Watermarked | |||||
| Mel |  |
 |
 |
 |
 |
Reference
- Kong Z, Ping W, Huang J, et al. DiffWave: A Versatile Diffusion Model for Audio Synthesis[C]//International Conference on Learning Representations. 2021.
- Chen N, Zhang Y, Zen H, et al. WaveGrad: Estimating Gradients for Waveform Generation[C]//International Conference on Learning Representations. 2021.
- Lee S, Kim H, Shin C, et al. PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Dependent Adaptive Prior[C]//International Conference on Learning Representations. 2022.
😊 Citation
If you find the code and dataset useful in your research, please consider citing our paper:
@inproceedings{liu2024groot,
title={GROOT: Generating Robust Watermark for Diffusion-Model-Based Audio Synthesis},
author={Liu, Weizhi and Li, Yue and Lin, Dongdong and Tian, Hui and Li, Haizhou},
booktitle={Proceedings of the 32nd ACM International Conference on Multimedia},
year={2024}
}